
LLVM을 사용한 Control Flow Flattening 패스 개발
LLVM을 이용하여 난독화를 할 수 있으면 이를 기반으로 다양한 플랫폼에서 LLVM을 사용하여 빌드되는 코드들에 대한 공통 난독화 툴을 만들 수 있을 것이라고 생각하였습니다.
이를 위해 여러가지 난독화 및 암호화 패스를 개발하였고 이 글에서는 그 중 한 가지인 흐름 평면화 패스의 개발 과정에 대해 소개하겠습니다.
LLVM이란
LLVM의 정식 명칭은 Low Level Virtual Machine입니다.
하지만 이 프로젝트의 핵심은 기존의 virtual machine 개념보다는 모듈화 되고 재사용 가능한 컴파일러 기술을 의미합니다. 그리고 이것은 target independent한 optimizer, target specific 한 어셈블리 코드를 생성하는 code generator 같은 컴파일러 도구들과 프로그래밍 언어와 어셈블리 코드 사이에 LLVM intermediate representation으로 알려진 LLVM IR이라는 중간 단계의 언어로 이루어져 있습니다.
이 글에서는 LLVM에서 모듈화된 컴파일러를 제작할 수 있는 구조인 패스를 통해 흐름 난독화를 하였습니다.
Control Flow Flattening란
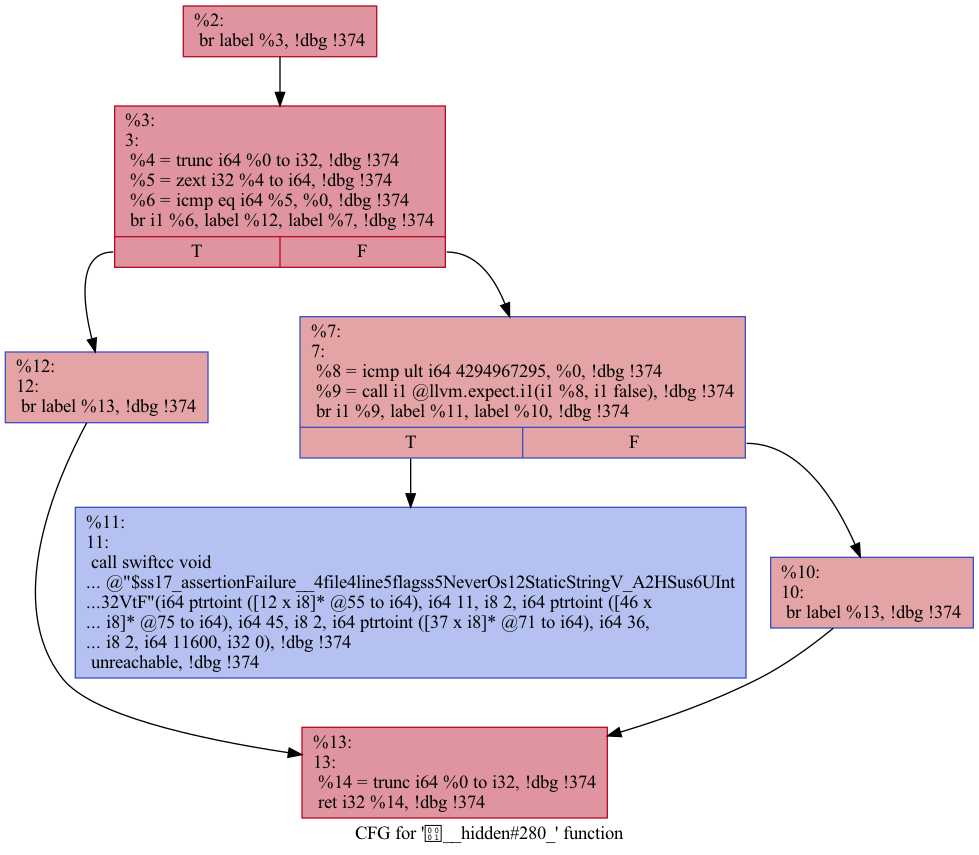
흐름 평면화, control flow flattening은 코드의 흐름을 평면화 시키는 난독화 기술입니다. Loop, conditional branch 같은 코드의 흐름을 전부 하나의 거대한 switch 문에 집어넣어서 모든 다른 블록으로의 이동이 단 하나의 블록으로부터 이루어지도록 만들어 코드를 분석하기 어렵게 만듭니다. 흐름 그래프가 마지막 사진과 같은 구조로 변경됩니다.
환경 구성
이 글에서는 llvm 13 버전을 바탕으로 LLVM을 빌드 하였습니다.
아래 cmake 명령이 정상적으로 실행된 후 ninja를 통해 빌드할 수 있습니다.
LLVM 개발은 샘플 패스인 llvm/lib/Transforms/Hello를 덮어씌워 흐름 평면화를 위한 커스텀 패스를 개발하였습니다.
cmake -G Ninja -DLLVM_PARALLEL_LINK_JOBS=1 -DCMAKE_BUILD_TYPE=Debug -DLLVM_ENABLE_PROJECTS=clang ../llvm-project/llvm
흐름 평면화 적용 시 발생하는 오류
LLVM에서 Function 클래스 아래에 존재하는 Basic Block들을 흐름 평면화의 개념에 따라 하나의 거대한 Switch Instruction 아래에 집어넣음으로써 구현해 낼 수 있습니다.
이처럼 수정을 시도할 경우 LLVM Verifier에서 수정된 내용이 유효한지 검증합니다. 흐름 그래프와 관련된 검증에는 preds라는 어떤 블록에서 이 블록으로 이동할 수 있는지에 대한 정보가 주로 사용되는데, 이와 관련된 아래 3가지 검증에서 오류가 자주 발생합니다.
-
phi node의 경우 모든 케이스와 preds가 일치해야 한다.
PHINode should have one entry for each predecessor of its parent basic block! %62 = phi i32 [ %30, %23 ], [ %35, %32 ], [ %40, %37 ], [ %60, %54 ], !dbg !1211 LLVM ERROR: Broken module found, compilation aborted! -
블록 A에서 호출하는 변수는 entry block에서 블록 A에 도달하기 전에 정의되어야 한다.
Instruction does not dominate all uses! %alloc = alloca i64, align 8 %load = load i64, i64* %alloc, align 8 LLVM ERROR: Broken module found, compilation aborted! -
Landingpad를 가진 블록은 반드시 invoke에 의해서 호출되어야 한다.
Block containing LandingPadInst must be jumped to only by the unwind edge of an invoke. LLVM ERROR: Broken module found, compilation aborted!이 문제들 중 1번과 2번은
opt에 기본으로 내장되어 있는 –reg2mem 옵션을 사용함으로써 대부분 해결할 수 있습니다. 이 옵션은 phi 노드들을 제거하고 모든 allocation을 entry block에서 하도록 수정해줍니다. 이를 적용함으로써 흐름 평면화를 진행하기 쉬워집니다. 다만 이 옵션을 적용하여도 남아있는 phi node가 있는 경우가 있어 이에 대한 예외처리를 해야 합니다.
3번의 경우 switch-case 블록에서 호출할 수 없기 때문에 예외처리를 해야 합니다.
평면화 코드 구현
우선 switch-case 문에서 호출할 수 있는 블록들을 확인해야합니다. Function 클래스에 iterator를 돌면서 위의 3번, LandingPad를 가졌는지 확인하고 아닌 것들을 벡터 형태로 수집합니다. Allocation이 이루어지는 블록은 따로 분리해 두어야 하기 때문에 entry block을 제거해주어야 합니다.
vector<BasicBlock *> origBB;
for (Function::iterator i = F.begin(); i != F.end(); ++i)
{
BasicBlock *block = &*i;
if (!block->isLandingPad())
{
origBB.push_back(block);
}
}
origBB.erase(origBB.begin());
return origBB;
그 다음 IRBuilder를 사용하여 Switch Instruction을 가지게 될 Basic Block을 만들어야 합니다. Switch 블록에는 default로 어떤 블록으로 점프할 것인지를 지정해 주어야 하는데 이것 역시 새로운 빈 블록, swDefault를 생성하여 지정해 주었습니다.
BasicBlock *swDefault = BasicBlock::Create(Context, "StealienCFGSwitchDefault", &F, *origBB.begin());
IRBuilder<> IRBswDefault(swDefault);
IRBswDefault.CreateBr(*origBB.begin());
BasicBlock *startSwitch = BasicBlock::Create(Context, "StealienCFGswitch", &F, swDefault);
IRBuilder<> IRBswitch(startSwitch);
그 다음 Switch에서 사용할 변수를 Entry Block에서 allocation을 해 준 뒤, Switch 블록에서 이 값을 Value add로 가져오도록 설정합니다.
AllocaInst *switchVar = new AllocaInst(llvm::Type::getInt64Ty(Context), AddrSpace, nullptr, AllocaAlign, "", entryBlock->getTerminator());
LoadInst *load = IRBswitch.CreateAlignedLoad(llvm::Type::getInt64Ty(Context), switchVar, MaybeAlign(8));
Value *add = IRBswitch.CreateAdd(load, ConstantInt::get(llvm::Type::getInt64Ty(Context), 762167));
그 후 IRBSwitch에 Switch Instruction을 생성합니다. randomArr은 특정 범위의 수를 랜덤한 순서로 섞은 리스트이며, 이 값들을 사용해서 아래와 같이 case들을 추가해줍니다.
switchI = IRBswitch.CreateSwitch(add, swDefault, randomArr[origBB.size()]);
for (BasicBlock *setSwitchBlocks : origBB)
{
BasicBlock *selectedBlock = setSwitchBlocks;
if(!this->hasPHI(selectedBlock)) {
ConstantInt *constCase = llvm::ConstantInt::get(llvm::Type::getInt64Ty(Context), randomArr[index]);
switchI->addCase(constCase, selectedBlock);
}
}
마지막으로 origBB에 있는 BasicBlock 들의 Terminator를 BranchInst인지 그리고 Successor 개수에 따라 분류할 수 있습니다. BranchInst는 1개 혹은 2개의 Successor를 가지며, 이것들이 수정 대상입니다.
- Branch Instruction이 아닌 경우 : return 혹은 unreachable 같은 종류되는 경우 혹은 invoke와 같이 수정이 불가능한 Terminating Instruction인 경우
- Branch Instruction의 Successor가 1인 경우 : branch BlockA 같이 다른 블록으로 이동하는 경우
- Branch Instruction의 Successor가 2인 경우 : branch condition BlockA BlockB 처럼 condition 값에 따라 이동하는 블록이 이동되는 경우
따라서 Branch Instruction에서 이동할 블록에 지정된 값을 Switch Instruction에서 찾아서 위에서 생성해둔 switchVar에 저장해주고 Switch Block으로 돌아가면 자동으로 이걸 로드해서 원하는 블록으로 이동하게 될 것입니다. Successor의 개수가 1인 경우에 대한 코드는 아래와 같습니다. 2인 경우에도 둘 다에 대해 동일하게 처리해주면 됩니다.
아래 코드에서는 Switch Instruction에서 가져온 intCase 값이 직접 드러나는 것을 숨기기 위해 추가적인 덧셈과 곱셈을 수행하도록 하였습니다.
if(!isa<BranchInst>(selectedBlock->getTerminator())){
continue;
}
uint64_t successors = selectedBlock->getTerminator()->getNumSuccessors();
if (successors == 1)
{
BasicBlock *follow = selectedBlock->getTerminator()->getSuccessor(0);
ConstantInt *intCase = switchI->findCaseDest(follow);
if (intCase == NULL)
{
continue;
}
selectedBlock->getTerminator()->eraseFromParent();
IRBuilder<NoFolder> tempBuilder(selectedBlock);
uint64_t origCase = intCase->getSExtValue() - addVal;
uint64_t randVal = 17+rand()%10000;
Value * mul = tempBuilder.CreateMul(ConstantInt::get(llvm::Type::getInt64Ty(Context), origCase/randVal), ConstantInt::get(llvm::Type::getInt64Ty(Context), randVal));
Value * add = tempBuilder.CreateAdd(mul, ConstantInt::get(llvm::Type::getInt64Ty(Context), origCase%randVal));
tempBuilder.CreateAlignedStore(add, switchVar, MaybeAlign(8));
tempBuilder.CreateBr(startSwitch);
}
전후비교
위와 같은 Control Flow Flattening 작업을 수행하면 아래와 같은 코드를 얻을 수 있습니다.
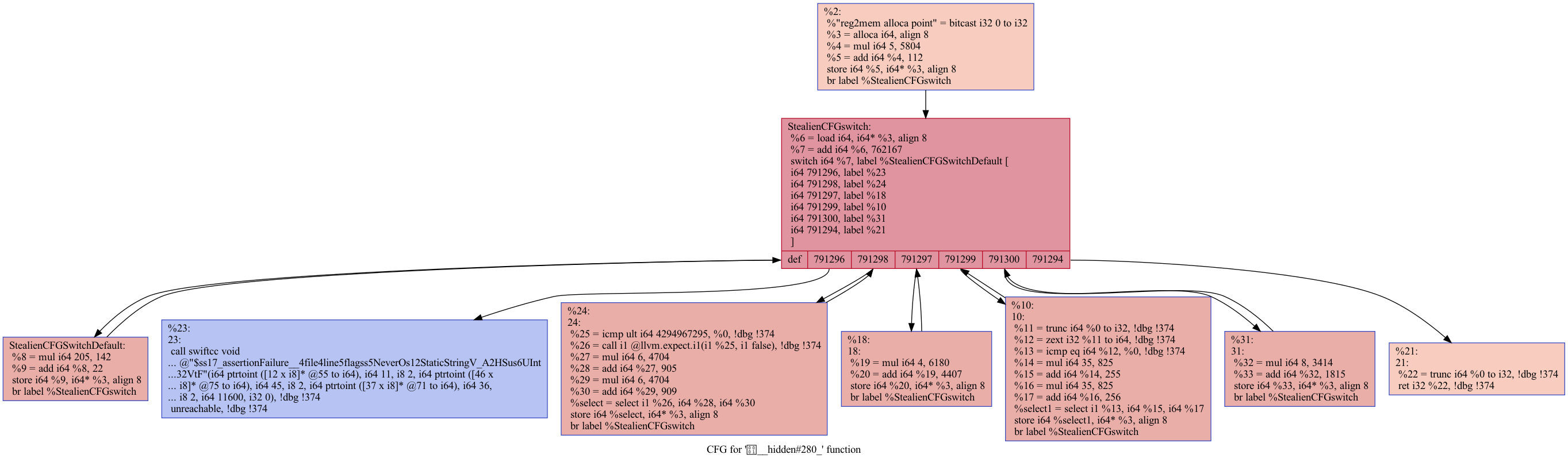
Opt의 -dot-cfg 옵션을 사용하여 흐름 평면화 전용 전과 후를 비교하면 StealienCFGswitch 라는 Switch 블록이 추가된 것과 모든 블록이 다시 이 블록으로 돌아가는 난독화 기능이 적용된 것을 확인할 수 있습니다.
이러한 난독화 기능은 다른 난독화 기능들과 함께 적용하면 훨씬 더 분석하기 어려운 코드를 만들어 낼 수 있습니다.
 |
|---|
| 기존 흐름 그래프 |
 |
|---|
| 평면화 모듈 적용 후 흐름 그래프 |